Spark Executor Memory - Simple Guide
This guide simplifies how memory is allocated within a Spark executor and what knobs you can tweak for better performance. If you’ve ever wondered what the different components of executor memory are, the diagram below breaks it down:
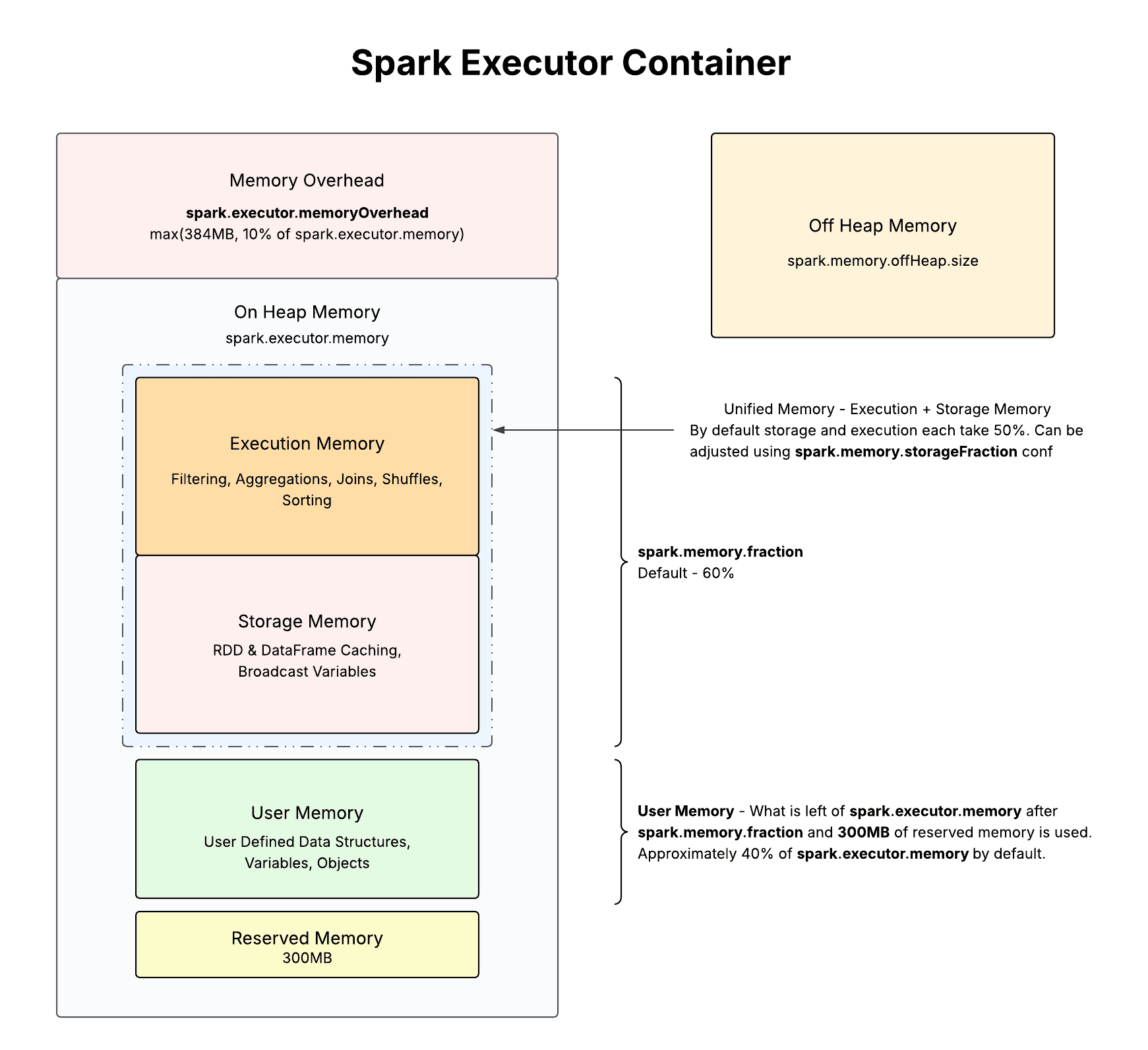
Let us first go through the different sections in the executor container memory.
The Spark Executor Container
The Spark executor is a JVM process launched on a worker node. Each executor has its own slice of memory that is logically divided into:
1. Memory Overhead
This includes off-heap memory and JVM overhead (like garbage collection). Default is:
1max(384MB, 10% of spark.executor.memory)This memory is outside the Java heap and is critical for things like Python worker processes (in PySpark) or native code execution.
Important thing to note here is that this memory is not a part of spark.executor.memory. So when you specify a spark.executor.memory as 10GB, the actual size of executor requested from cluster is 10GB + 10% of 10GB = 11GB.
2. On-Heap Memory
Set using spark.executor.memory. This is the main memory Spark uses and is further split into:
2.1 Unified Memory
By default, 60% of spark.executor.memory is allocated to this unified memory (controlled by spark.memory.fraction). Unified Memory is divided in Execution Memory and Storage Memory. By default, each gets 50% of the unified space, governed by spark.memory.storageFraction (default 0.5).
Execution Memory
Used for shuffles, joins, sorts, and aggregations - basically, all runtime computations.
Storage Memory
Used for caching RDDs/DataFrames and holding broadcast variables.
If one side doesn't need all its allocated share, the other can borrow it:
- If nothing is cached, execution can temporarily use the entire unified memory.
- If no computation is ongoing, storage can fill up more memory with cached data.
If Storage runs out - Least Recently Used (LRU) cached blocks are evicted to free up memory
If Execution runs out - Task fails with an OOM error - there’s no eviction fallback here
Here’s how you can optimize for different scenarios:
- Shuffle-heavy jobs? - Increase execution memory (spark.memory.storageFraction = 0.2)
- Cache-heavy workloads? - Give more room to storage (spark.memory.storageFraction = 0.7)
2.2 User Memory
This is what’s left after removing spark.memory.fraction and the 300MB reserved memory. It’s used for user-defined data structures, variables, and objects, and typically amounts to ~40% of the total executor memory.
2.3 Reserved Memory
Has a fixed size of 300MB. Spark reserves this chunk to avoid running out of memory during operations.
3. Off-Heap Memory
Set using spark.memory.offHeap.size. If enabled (spark.memory.offHeap.enabled=true), Spark can allocate memory outside the JVM heap, useful for Tungsten-optimized operations or memory-mapped files.
Off-heap memory doesn’t sit in the JVM heap, so it’s not scanned or cleaned by the GC. This is great for large-scale jobs where GC pauses can slow things down significantly.
Summary
To summarize, here’s how Spark organizes memory inside an executor:
- Memory Overhead
This is memory outside the Java heap, used for off-heap allocations, Python workers (in PySpark), and other native processes. It’s not part of spark.executor.memory.- Default: 10% of spark.executor.memory, controlled by spark.executor.memoryOverhead.
- On-Heap Memory
This is the main memory allocated to the executor, configured via spark.executor.memory.- Unified Memory (default 60% of spark.executor.memory)
- Execution Memory: Used for shuffles, joins, sorts, and aggregations.
- Storage Memory: Used for caching DataFrames, RDDs, broadcast variables, etc.
This split is dynamic and managed by Spark internally, controlled by spark.memory.fraction.
- User Memory (remaining ~40%)
Used for internal Spark metadata, user-created data structures, and temporary objects. This portion isn’t managed by the unified memory manager. - Reserved Memory (~300MB)
Fixed amount reserved for Spark's internal needs (like task metrics, etc).
- Unified Memory (default 60% of spark.executor.memory)
So if you set spark.executor.memory to 10GB, Spark allocates 10GB for on-heap use, and adds ~10% extra as overhead — resulting in a total container memory of ~11GB requested from the cluster.
Some Tips
- Monitor executor memory usage via Spark UI.
- Increase overhead if you get out-of-memory errors from native libraries (especially in PySpark).
- Balance caching and computation – cached RDDs/DataFrames can evict execution memory if not managed.
Mastering executor memory is crucial for scaling Spark applications. A well-tuned executor can save you from memory errors and improve job performance drastically.