Top 15 PySpark Interview Questions and Answers for 2025
Common PySpark Interview Topics
To excel in a PySpark interview, focus on these core concepts:
- RDDs (Resilient Distributed Datasets): The building blocks of Spark that allow fault-tolerant parallel computations.
- DataFrames: Higher-level APIs built on top of RDDs that provide powerful data manipulation features similar to Pandas.
- Spark SQL: A module for processing structured data using SQL queries.
- Transformations & Actions: Understanding lazy evaluations and Spark operations is crucial.
- Joins & Aggregations: Efficiently joining datasets and performing group-wise computations.
- Performance Optimization: Techniques like partitioning, caching, and broadcast joins.
- Handling CSV and JSON Data: Loading and processing structured data formats in PySpark.
Also prepare for PySpark Coding Rounds. You will be asked to solve coding questions in PySpark or SQL. You can solve PySpark coding questions online here - PySpark Coding Questions
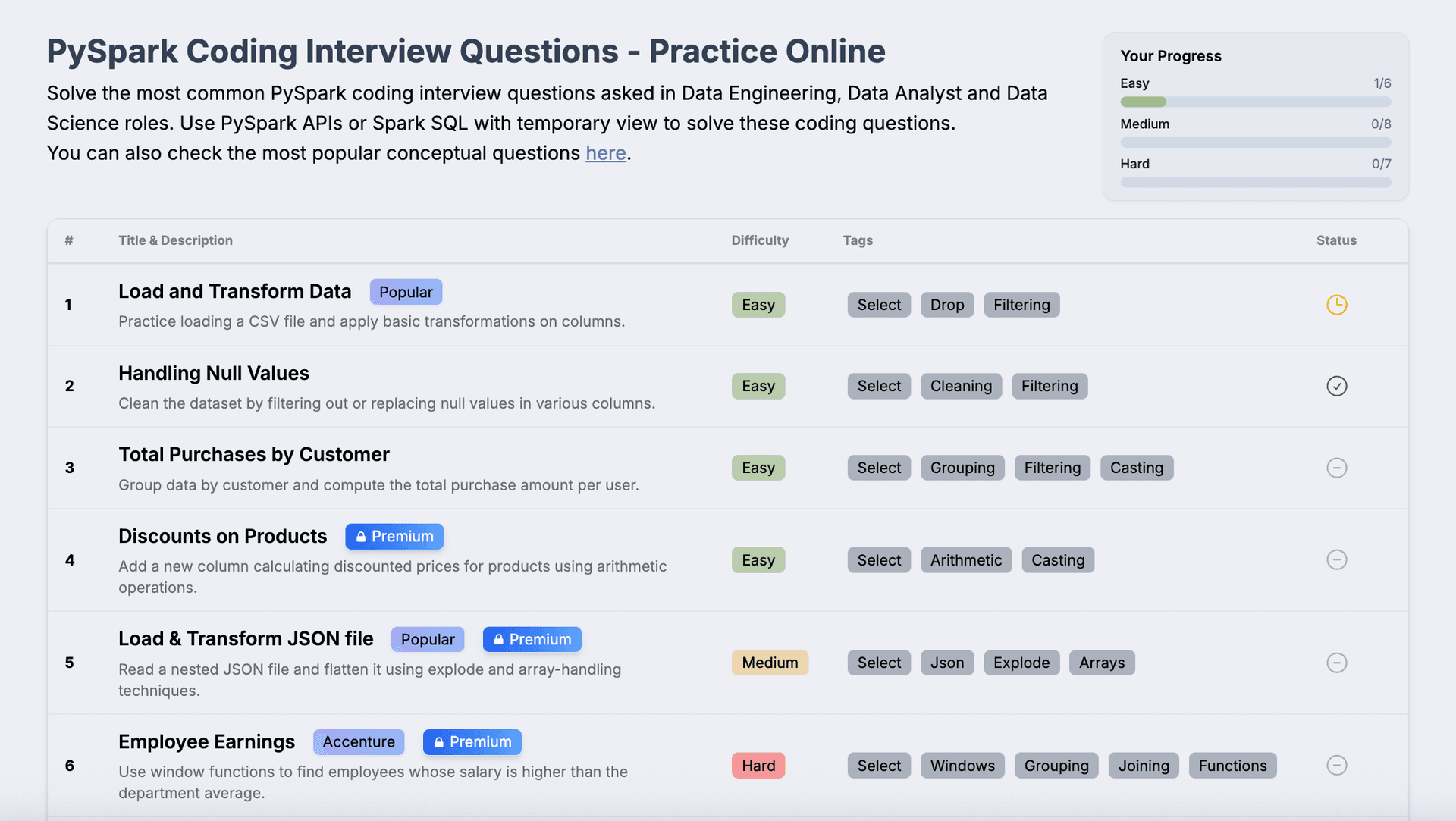
Top PySpark Interview Questions
1. What are RDDs, and how do they differ from DataFrames?
Answer:
RDDs (Resilient Distributed Datasets) are the fundamental data structure in Spark, allowing parallel processing. DataFrames, on the other hand, provide higher-level optimizations and use a schema similar to tables in a database.
When to use RDDs:
- Complex data processing workflows
- Low-level transformations
- No fixed schema
When to use DataFrames:
- Structured data
- SQL-style queries
- Performance-critical applications
2. How do you create a DataFrame in PySpark?
Answer:
You can create a DataFrame from a list, dictionary, or an external file like CSV or JSON.
1from pyspark.sql import SparkSession
2
3spark = SparkSession.builder.appName("Example").getOrCreate()
4
5data = [("Alice", 25), ("Bob", 30)]
6columns = ["Name", "Age"]
7
8df = spark.createDataFrame(data, columns)
9df.show()3. What is the difference between transformations and actions in PySpark?
Answer:
Transformations (like map(), filter(), groupBy()) create new RDDs but are lazily evaluated.
Actions (like collect(), count(), show()) trigger computation and return results.
4. How do you optimize a PySpark job?
Answer:
Some common techniques include:
- Using broadcast joins for small datasets.
- Repartitioning data effectively to avoid data skew.
- Caching frequently used DataFrames using .cache() or .persist().
- Avoiding shuffling by using coalesce() where needed.
5. How do you read and write CSV files in PySpark?
Answer:
1# Reading a CSV file
2df = spark.read.csv("path/to/file.csv", header=True, inferSchema=True)
3
4# Writing to a CSV file
5df.write.csv("output/path", header=True)6. How do you perform a join between two DataFrames in PySpark?
Answer:
1df1 = spark.createDataFrame([(1, "Alice")], ["id", "name"])
2df2 = spark.createDataFrame([(1, "NYC")], ["id", "city"])
3
4result = df1.join(df2, on="id", how="inner")
5result.show()7. What is a broadcast join and when would you use it?
Answer:
A broadcast join copies a small DataFrame to all nodes in the cluster to avoid shuffling large datasets. Use it when one DataFrame is small enough to fit in memory.
1from pyspark.sql.functions import broadcast
2
3result = df1.join(broadcast(df2), on="id")8. Explain the difference between repartition() and coalesce().
Answer:
- repartition() increases or decreases partitions by shuffling the data.
- coalesce() decreases the number of partitions without a full shuffle, making it more efficient for reducing partitions.
9. How do you handle missing or null values in a DataFrame?
Answer:
1df.na.drop() # Drops rows with any null values
2df.na.fill(0) # Replaces nulls with 0
3df.na.replace("NA", None) # Replaces 'NA' string with None10. What are some common performance bottlenecks in PySpark?
Answer:
- Inefficient joins
- Skewed data
- Excessive shuffling
- Lack of caching
- Small partition sizes or too many partitions
11. What is skewed data in PySpark, and how do you handle it?
Answer:
Skewed data occurs when certain keys in a dataset appear far more frequently than others, causing uneven data distribution during operations like joins or aggregations. This leads to performance bottlenecks because some tasks take significantly longer to execute.
To handle skewed data in PySpark, common techniques include:
- Salting the skewed key to distribute data more evenly
- Using broadcast joins when one side of the join is small
- Filtering out skewed keys and processing them separately
These approaches help balance the workload across executors and improve overall job performance.
12. What are the different data formats you use in PySpark?
Answer:
PySpark supports a variety of data formats for reading and writing data efficiently. The most commonly used ones include:
- CSV: Simple and widely used, but lacks schema information and doesn't support complex types.
- JSON: Human-readable and supports nested structures; slower and more verbose than binary formats.
- Parquet: Columnar, compressed, and efficient for queries on specific columns. Ideal for big data processing.
- ORC: Similar to Parquet, optimized for the Hadoop ecosystem; best for Hive workloads.
- Avro: Row-based, schema-evolution-friendly, and good for streaming or serialization.
- Delta: Built on Parquet with support for ACID transactions, versioning, and efficient updates.
Each format has trade-offs in terms of read/write speed, compression, schema evolution, and compatibility, so the choice depends on the specific use case.
13. How does Spark handle fault tolerance?
Answer:
Spark handles fault tolerance using a concept called lineage. Instead of replicating data across nodes, Spark tracks the sequence of transformations (like map, filter, etc.) used to build each RDD. If a partition is lost due to a node failure, Spark recomputes only the lost data using the original transformations.
For example, if a node crashes during execution, Spark can re-run just the failed task on another node by using the RDD’s lineage information.
Additionally:
- For cached or persisted data, Spark will recompute the lost partitions only if needed.
- For shuffle operations, Spark stores intermediate files on disk so failed tasks can be retried.
This approach avoids the overhead of data replication and still ensures reliable recovery during failures.
14. What is the difference between narrow and wide transformations in Spark?
Answer:
In Spark, transformations are categorized into narrow and wide based on how data is shuffled across partitions.
Narrow Transformations
- Data required to compute the records in a single partition resides in the same partition of the parent RDD.
- There is no data shuffling across the cluster.
- These are fast and efficient.
- Examples: map(), filter(), union(), sample()
Wide Transformations
- Data from multiple partitions may be required to compute a single partition in the child RDD.
- This involves a shuffle i.e. data is moved across the network.
- These are slower and more expensive.
- Examples: groupByKey(), reduceByKey(), join(), distinct()
We should try to optimize jobs by minimizing wide transformations when possible.
15. What is the Catalyst Optimizer in Spark?
Answer:
The Catalyst Optimizer is Spark's query optimization engine used primarily with DataFrames and Spark SQL. It automatically analyzes, rewrites, and optimizes query plans to improve performance without manual intervention. Its key features are:
- Logical Plan Optimization
Rewrites the query using rules like constant folding, predicate pushdown, and projection pruning. - Physical Plan Generation
Evaluates multiple physical plans and selects the most efficient one based on cost. - Extensibility
Catalyst is built using functional programming (Scala), making it easy to plug in new optimization rules.
Example:
For the query:
1df.filter("age > 30").select("name")Catalyst may:
- Push the filter closer to the data source.
- Remove unused columns - Spark will not read the unused columns from the data source.
- Choose an optimized join strategy if joins are involved.
Final Tips to Ace Your PySpark Interview
- Practice coding challenges on real-world datasets here.
- Understand distributed computing concepts and how Spark executes tasks.
- Be comfortable with SQL queries in Spark.
- Know how to debug PySpark jobs and handle performance bottlenecks.
- Use Spark Playground to test your PySpark skills online.
Preparing for a PySpark interview requires hands-on practice and a solid understanding of Spark's core concepts. Keep coding and refining your approach to common problems. Happy learning!