⚡ Introduction to Apache Spark
Apache Spark is an open-source, distributed data processing engine designed for fast, scalable processing of large datasets. It provides in-memory computing capabilities that make it significantly faster than traditional disk-based processing frameworks, particularly for iterative algorithms and real-time analytics.
Spark: Origins and Fundamentals
What is Apache Spark?
Apache Spark is a unified analytics engine that provides parallel and distributed processing of big data workloads. It offers a comprehensive ecosystem of libraries for batch processing, SQL queries, streaming data, machine learning, and graph computation, all integrated into a single framework.
When Was It Developed?
- Spark originated in 2009 as a research project at UC Berkeley's AMPLab (Algorithms, Machines, and People Lab)
- AMPLab was a collaboration among students, researchers, and faculty focused on data-intensive applications
- Open-sourced in early 2010 under a BSD license
- Transferred to the Apache Software Foundation in June 2013
Why Was It Created?
Spark was created to address the limitations of Hadoop MapReduce, particularly its inefficiency for iterative processing required by machine learning algorithms and interactive data analysis. The goal was to build a framework optimized for fast iterative processing while retaining the scalability and fault tolerance of Hadoop MapReduce.
How Does It Work?
Spark processes data by keeping it in memory (RAM) rather than writing to disk after each operation. It uses a Directed Acyclic Graph (DAG) execution engine that optimizes task scheduling and reduces latency by eliminating unnecessary disk I/O operations. Spark Core provides essential services like task scheduling, memory management, fault recovery, and job execution, while higher-level components handle specific workloads.
Issues with Traditional Systems
Traditional data processing systems face several critical limitations when handling big data:
- Scalability bottlenecks: Traditional systems scale vertically (adding more powerful hardware to a single machine) rather than horizontally, quickly hitting hardware limits as data grows from gigabytes to terabytes
- Lack of real-time processing: Designed primarily for batch processing, traditional systems cannot support real-time analytics needed for modern use cases like fraud detection and personalized experiences
- Performance issues: Centralized relational databases slow down significantly as data volume increases, with each operation taking longer due to sequential processing
- Inflexibility with data types: Traditional systems handle only structured data in rigid schemas, missing approximately 80% of available data that exists in unstructured or semi-structured formats
- High costs: Scaling traditional systems requires expensive hardware upgrades and enterprise database licenses, with costs escalating exponentially
Hadoop MapReduce
Hadoop MapReduce is a programming model for processing large datasets in a distributed computing environment. It divides tasks into two independent phases: the Map phase (which filters and sorts data) and the Reduce phase (which performs summary operations). While MapReduce introduced horizontal scalability and fault tolerance, it processes data by writing intermediate results to disk after each operation, creating significant I/O overhead.
MapReduce vs Spark Comparison
| Aspect | Hadoop MapReduce | Apache Spark |
|---|---|---|
| Processing Speed | Slower due to disk-based storage between operations | 100x faster in-memory, 10x faster on disk |
| Data Storage | Stores intermediate results on local disk | Caches data in RAM across distributed workers |
| Execution Model | Rigid sequential map and reduce phases | DAG-based execution with optimized task scheduling |
| Fault Tolerance | Replicates data to disk; re-reads from HDFS on failure | Uses lineage tracking; recomputes lost partitions from source data |
| Processing Type | Primarily batch processing | Batch, real-time streaming, interactive queries |
| Ease of Use | Complex, requires more code | User-friendly APIs in multiple languages |
| Iterative Processing | Inefficient for machine learning algorithms | Optimized for iterative algorithms |
| Latency | High I/O overhead creates bottlenecks | Low latency with in-memory computation |
| Cost | Lower hardware requirements | Requires more memory resources |
Spark Ecosystem
The Unified Stack Architecture
The provided image illustrates Apache Spark as a layered, unified stack where higher-level libraries rely on the core engine, allowing developers to use different languages and data sources seamlessly.
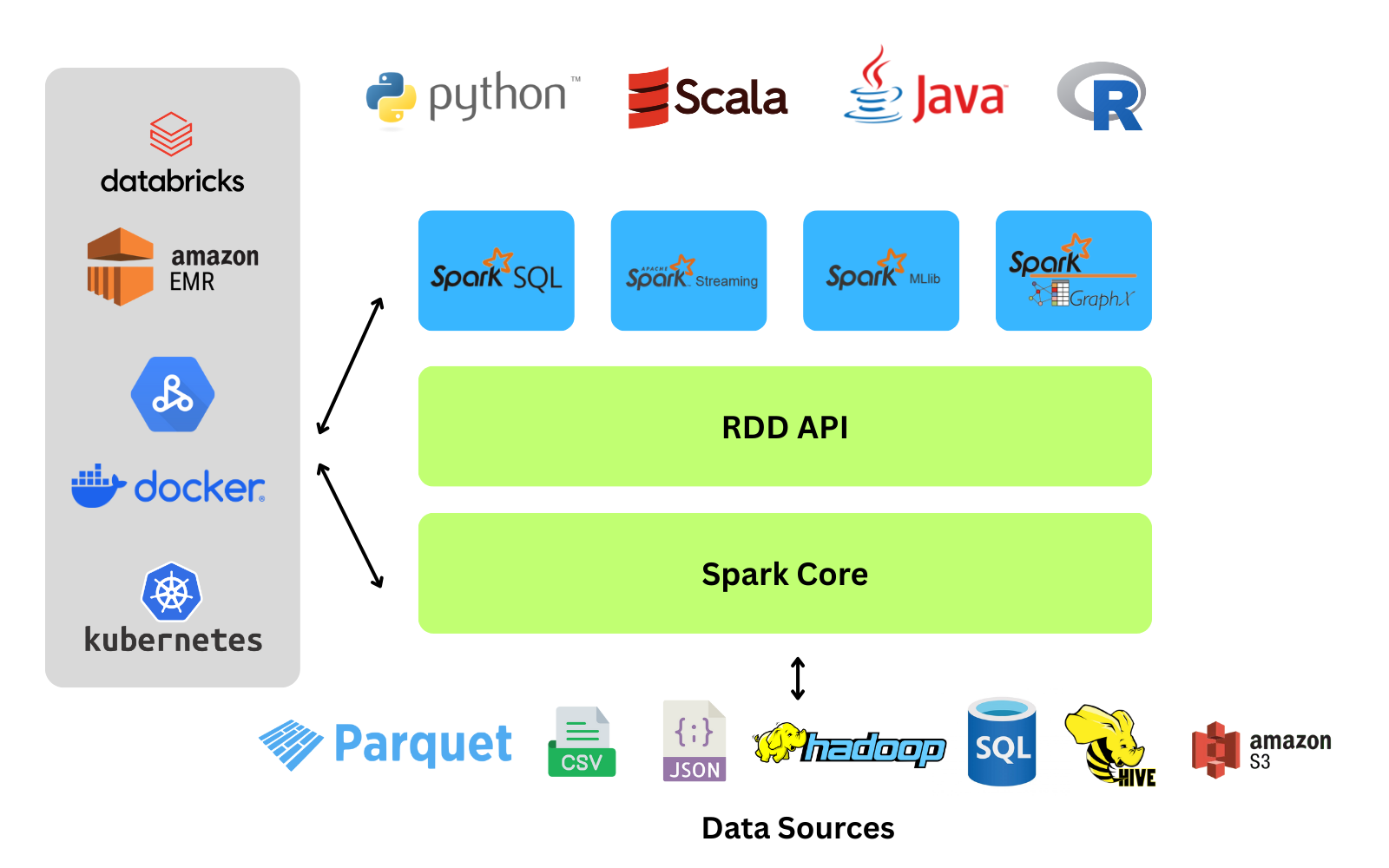
1. Language APIs (Top Layer) At the very top, the diagram shows support for four major programming languages:
- Python
- Scala
- Java
- R
This flexibility allows Data Engineers and Data Scientists to interact with Spark using the language they are most comfortable with, without needing to learn low-level cluster programming.
2. Domain-Specific Libraries (Blue Layer) The four blue boxes represent Spark's built-in libraries that handle specific data workload types:
- Spark SQL: For processing structured data using SQL queries and DataFrames.
- Spark Streaming: For ingesting and processing real-time data streams.
- Spark MLlib: A library of machine learning algorithms for tasks like classification and clustering.
- Spark GraphX: For graph computation and network analysis.
3. The Core Engine (Green Layers) The foundation of the stack is depicted by the two green bars: Spark Core and the RDD API.
- Spark Core: This is the underlying execution engine responsible for memory management, task scheduling, and fault recovery.
- RDD API: Sitting directly on top of the core, this exposes the Resilient Distributed Dataset abstraction, which is the fundamental data structure Spark uses to process data in parallel across the cluster.
4. Deployment Environment (Left Panel) The "Environment" section on the left illustrates that Spark is decoupled from the resource manager. It can run in various environments:
- Containerized: Using Docker or Kubernetes.
- Cloud: On services like Amazon EC2, Databricks, Google DataProc.
- Cluster Managers: natively on Mesos or OpenStack.
5. Data Sources (Bottom Layer) The bottom section shows Spark's ability to connect to a wide variety of data storage systems. Instead of locking you into a single storage format, it can ingest data from:
- Cloud Storage: ADLS, GCS, AWS S3.
- Hadoop Ecosystem: HDFS (Hadoop), Hive, and HBase.
- NoSQL Databases: Cassandra, Elasticsearch, MongoDB, Redis, and DynamoDB.
- Relational Databases: MySQL, PostgreSQL, Oracle, SQL Server, and Redshift.
- Flat Files: CSV, JSON, Parquet, Avro, and ORC formats.
- Streaming Sources: Apache Kafka, Kinesis, and event hubs for real-time data ingestion.
- Cloud Data Warehouses: Snowflake, BigQuery, and Databricks Delta Lake.
Spark achieves this flexibility through connectors - specialized libraries that enable reading and writing to specific systems. Many are built-in, while others are available through third-party packages that you can add to your Spark application.