🔄 Transformations & Actions
Transformations and actions are the two building blocks of every Spark job: transformations define what should happen to data, and actions trigger execution to produce a result or write output. This split is what enables Spark’s lazy evaluation and efficient optimization via its execution plan (DAG).
Understanding the Basics
A transformation creates a new RDD/DataFrame from an existing one (it describes a step in your pipeline - like a select, filter, join etc) and is evaluated lazily. An action asks Spark to materialize a result (return to the driver, write to storage, or otherwise “finish” the computation), which is what triggers a job in Spark’s execution model.
Transformations: Defining What to Do
Transformations are “recipe steps” that Spark records in the lineage/DAG rather than executing immediately, allowing Spark to optimize the plan before running it. Common transformation examples include select, filter, withColumn, groupBy, join, distinct, repartition, and union.
Before we understand the 2 types of transformations, we need to know what partitions are in Spark.
What are Partitions?
At its core, Spark achieves parallelism by splitting your data into smaller chunks called partitions.
A partition is a logical division of your dataset that lives on a single machine in the cluster. Think of it as a slice of your total data. When you load a 1GB CSV file, Spark doesn't process it as one giant blob - it splits it into, say, 8 partitions of ~128MB each, distributing them across your executors.
Why Partitions Matter
Partitions are the fundamental unit of parallelism in Spark. Remember this equation from earlier:
1 Partition = 1 Task = 1 Core
If your DataFrame has 200 partitions and your cluster has 40 cores (10 executors × 4 cores), Spark processes:
- First wave: 40 partitions in parallel
- Second wave: Next 40 partitions
- ...and so on until all 200 are done
This is why the number of partitions directly impacts how fast your job runs.
The Default Behavior
When you read data, Spark automatically creates partitions based on:
- File size: Larger files get split into more partitions
- Data source: HDFS block size, number of CSV files in a folder, etc.
spark.sql.files.maxPartitionBytes: Default is 128MB per partition
You can check the partition count with:
df.rdd.getNumPartitions()
And manually control it using repartition() or coalesce() (we'll cover these in depth later).
Now, coming back to Transformations - Two useful sub-types matter for performance:
-
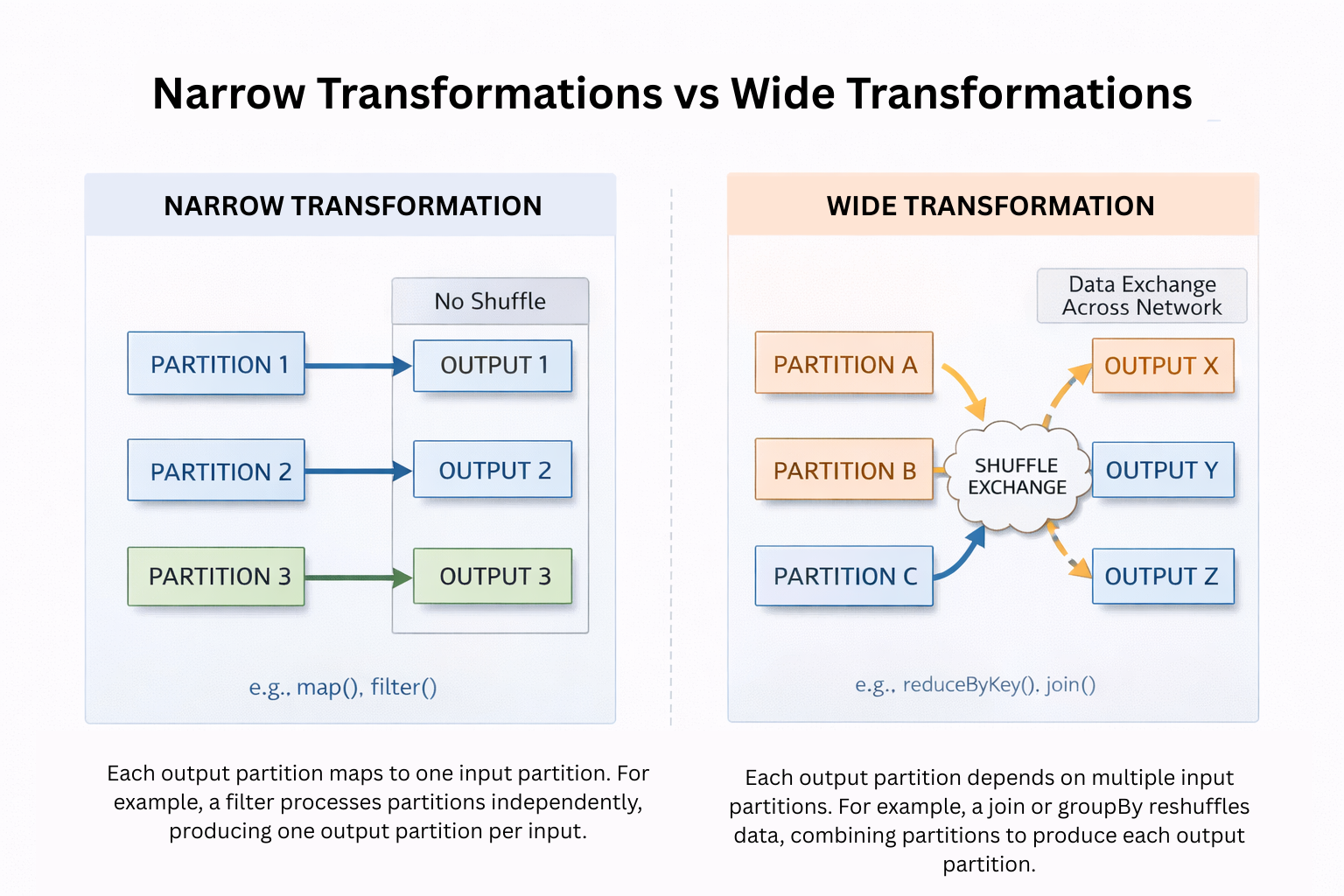
Narrow transformations: Each output partition depends on a single input partition (no data movement needed), e.g.,
filter,map,select. These are fast because each executor works independently on its own partitions. -
Wide transformations: Output partitions require data from multiple input partitions across the cluster (causes shuffle), e.g.,
groupBy,join,distinct,repartition.
Why the shuffle? Consider a groupBy("customer_id") operation on a 100-partition DataFrame. Customer "C123" might have records scattered across partitions 5, 23, 47, and 89 on different executors. To calculate the correct aggregate (like sum(amount)), Spark must:
- Shuffle: Move all "C123" records from their current partitions across the network to land on the same partition
- Aggregate: Once co-located, sum up the amounts
Performance Implications of Transformations
1. Narrow Transformations: Pipelining (High Efficiency)
- No Data Movement: Since the data required for the computation resides on the same partition, there is no need to transfer data over the network between executors.
- Pipelining: Spark optimizes narrow transformations by collapsing them into a single stage. For example, if you write
df.filter(...).map(...).select(...), Spark fuses these three operations into a single task. The engine reads a record, filters it, maps it, and selects it in one pass, without writing intermediate results to memory or disk. - Speed: These are extremely fast and memory-efficient.
2. Wide Transformations: The Shuffle Cost (High Overhead)
- The Shuffle: This is the most expensive operation in Spark. It involves:
- Disk I/O: Writing intermediate data to disk (spilling) to ensure fault tolerance and memory management.
- Network I/O: Transferring data across different nodes in the cluster to group related keys together.
- Serialization/Deserialization: Significant CPU overhead to serialize data for transport and deserialize it at the destination.
- Stage Boundaries: Wide transformations break the execution plan (DAG) into Stages. Spark cannot proceed to the next stage until the current stage (the shuffle) is complete. This acts as a blocking operation, preventing parallelization across the boundary.
- Data Skew: Wide transformations are prone to data skew. If one key (e.g., a popular
customer_id) has significantly more data than others, one partition will become massive, causing the specific executor processing it to run out of memory (OOM) or lag behind the others (straggler tasks).
Actions: The Go Button
Actions force Spark to execute the DAG and either return something to the driver or write results externally. Typical actions include count, collect, take, first, show, write.save(...), and (in RDD land) reduce.
A practical way to think about it:
- Transformations = “build the plan”
- Actions = “run the plan now” (and Spark breaks it into jobs/stages/tasks during execution)
Spark behavior in practice
The transformation steps in your code feel instant because Spark doesn't execute them yet. When you call an action, Spark runs everything needed to produce that result. If you call two actions on the same DataFrame without caching, Spark recomputes all the work twice.
Example (PySpark DataFrame):
df2 = (df
.filter("country = 'IN'") # narrow transformation (each input partition is filtered independently -> produces one output partition per input partition)
.select("user_id", "amount") # narrow transformation (columns are selected per partition independently)
.groupBy("user_id").sum("amount") # wide transformation (shuffle happens -> same user_id across partitions end up in the same partition -> amounts are summed)
)
df2.show(10) # action -> triggers a job
df2.count() # action -> may trigger another job (recompute) unless cached
Transformation vs action
| Aspect | Transformations | Actions |
|---|---|---|
| What it does | Defines a new dataset from an existing one | Materializes a result (driver/output sink) |
| Execution | Lazy (builds lineage/DAG) | Triggers execution (job starts) |
| Typical output | Another DataFrame/RDD | A value, a collection, or written data |
Narrow vs Wide Transformations
| Aspect | Narrow | Wide |
|---|---|---|
| Partition dependency | 1-to-1 (each output partition depends on only one input partition) | Many-to-many (output partitions need data from multiple input partitions) |
| Shuffle required | No shuffle | Shuffle required |
| Data movement | Local operation within partition | Data redistributed across network |
| Stage boundary | No new stage created | Creates new stage |
| Examples | filter, select, withColumn, map | groupBy, join, distinct, repartition |