🧂 Data Skew and Salting
Data skew is one of the most frustrating performance problems in Spark. Your job is 95% complete, 199 tasks finished in seconds, and one task is still running... grinding for 45 minutes. Let's understand why it happens.
What is Data Skew?
We say that the data is skewed when data is unevenly distributed across partitions, causing some partitions to hold far more records than others. Since each partition is processed by a single CPU core, a skewed partition means one core is overloaded with massive amounts of data while all other cores finish quickly and sit idle wasting cluster resources and bottlenecking your entire job.
When you perform a wide dependency transformation like a groupBy, join, or aggregation on a key column, Spark shuffles rows with the same key to the same partition. If your data is uneven, for example - 60% of your orders belong to a single customer_id, then that one partition becomes a skewed partition: it bottlenecks your entire job.
How to detect skew:
- Spark UI → Stages tab → look at task duration distribution
- A task taking 10x–100x longer than the median is a red flag
- Look for a massive difference in input size per task in the shuffle read column
# Quick skew check to inspect key distribution before joining or grouping
df.groupBy("customer_id").count().orderBy("count", ascending=False).show(20)
If the top keys carry a disproportionate share of rows, you have skew.
The Five Ways to Handle Data Skew
- Salting techniques to manually distribute hot keys across partitions
- AQE Skew Join feature to let Spark handle it automatically (Spark 3.x)
- Broadcast Join strategy to eliminate the shuffle entirely
- Split and Union to process outlier keys separately
- Pre-Aggregation to reduce data volume before the join
1. Salting
Salting artificially distributes skewed keys across multiple partitions by appending a random integer (the "salt") to the key. This breaks one massive partition into N smaller, balanced ones.
Salting = add a random suffix to the hot key on the large side, and in case of joins - explode the small side to match all possible suffixes.
Since salting changes the key, so the implementation differs slightly between aggregations and joins.
Salting for GroupBy / Aggregation
The idea is simple: salt the key to spread the hot partition across multiple smaller partitions, run a partial aggregation on each, then strip the salt and do a final aggregation to combine the partial results.
For example, say
customer_id = 'C001'has 10 million rows and you want the totalamountfor each customer. WithSALT_BUCKETS = 5, those 10 million rows get split into 5 groups:'C001_0'through'C001_4', each holding ~2 million rows.Spark computes a partial sum on each group in parallel — say
120,95,110,130,145. In the second phase, the salt is stripped and these five partial sums are combined into a single final sum of600for'C001'. The math is identical, just the work is distributed.
The Problem:
# Causes skew if customer_id is highly unbalanced
df.groupBy("customer_id").agg(F.sum("amount").alias("total"))
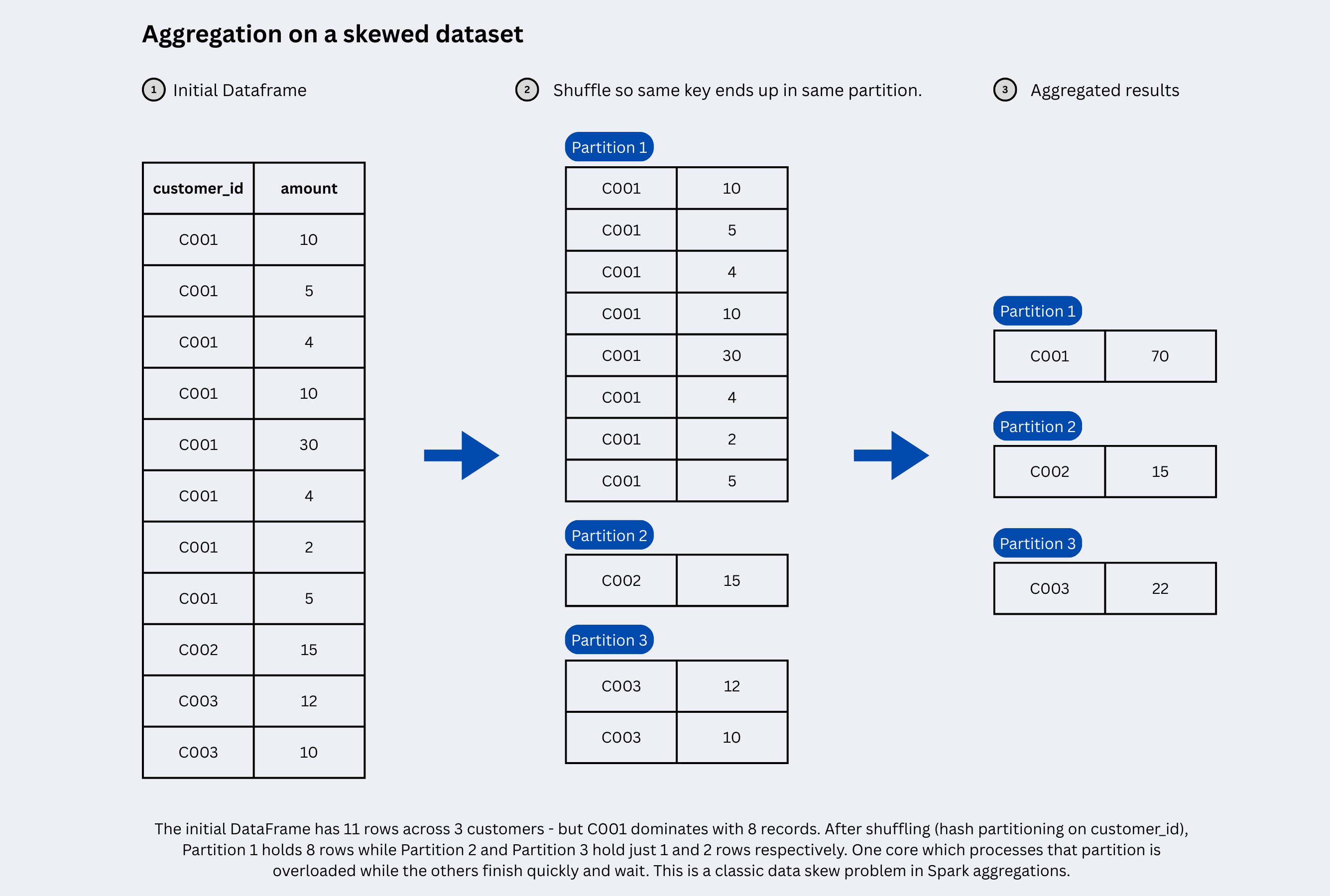
This is how we apply salting and prevent unevenly distributed partitions in aggregations:
Step 1: Add salt, pre-aggregate:
from pyspark.sql import functions as F
SALT_BUCKETS = 10 # tune based on skew severity
salted_df = df.withColumn(
"salted_key",
F.concat(F.col("customer_id"), F.lit("_"), (F.rand() * SALT_BUCKETS).cast("int"))
)
pre_agg = salted_df.groupBy("salted_key", "customer_id").agg(
F.sum("amount").alias("partial_sum")
)
Step 2: Strip salt, final aggregation:
final_agg = pre_agg.groupBy("customer_id").agg(
F.sum("partial_sum").alias("total")
)
Let's see how the aggregation happens behind the scenes now:
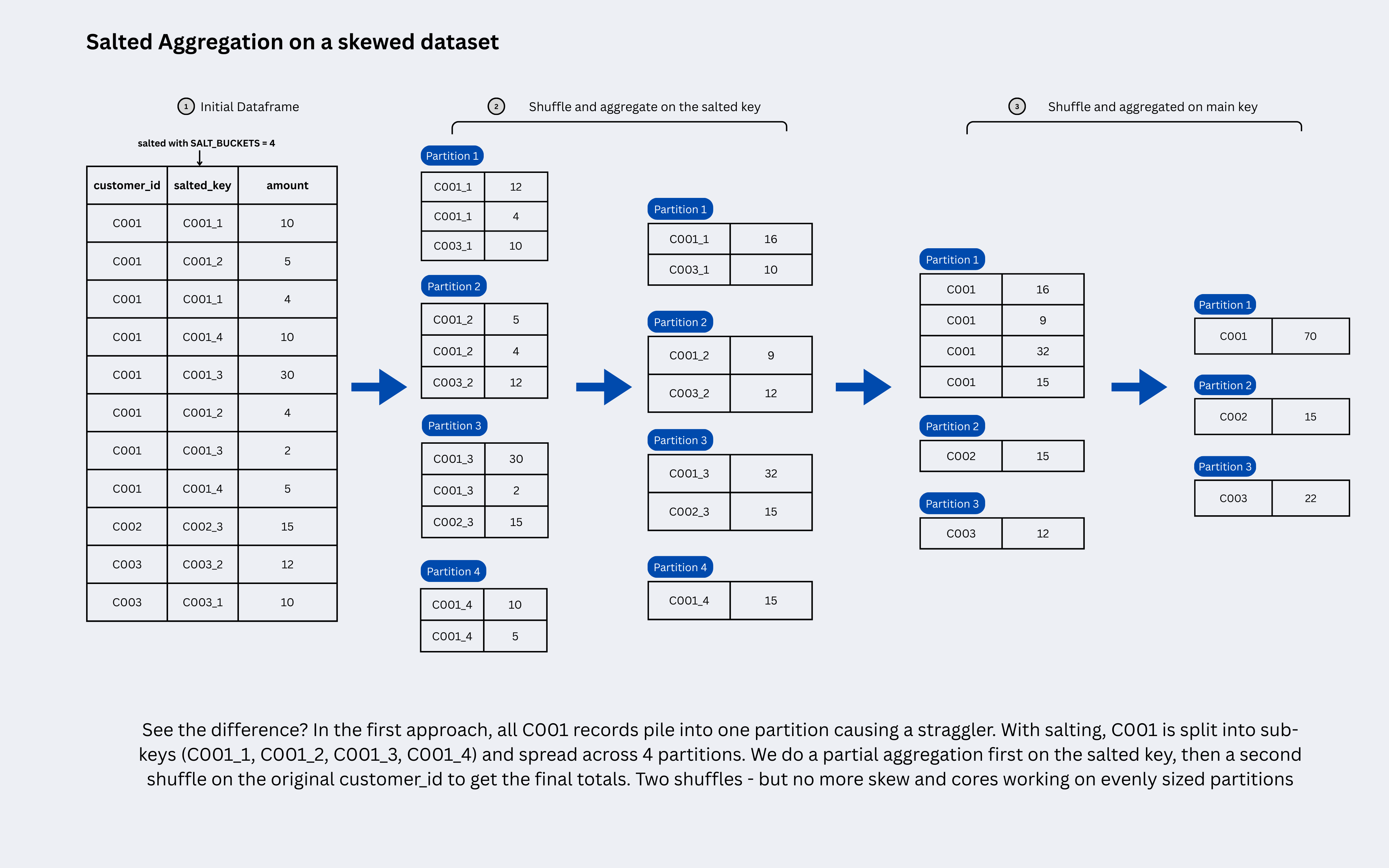
Salting for Joins
In a regular join, Spark matches rows from both sides using the same key: say customer_id = 'C001'. When you salt the large side, 'C001' becomes 'C001_0', 'C001_3', 'C001_7' and so on, depending on the random salt assigned to each row. Now the small side still has 'C001', it has no idea what 'C001_3' is, so you cannot proceed with the join.
To fix this, you explode the small side: you create SALT_BUCKETS copies of every row, each with a different salt suffix appended. So 'C001' becomes 'C001_0', 'C001_1', all the way to 'C001_9'. Now for every salted key on the large side, there is guaranteed to be a matching row on the small side, and the join works correctly.
The Problem:
# orders has 60% rows for customer_id = 'C001' — classic skew
orders.join(customers, "customer_id")
Step 1: Salt the large (skewed) side:
SALT_BUCKETS = 10
salted_orders = orders.withColumn(
"salt", (F.rand() * SALT_BUCKETS).cast("int")
).withColumn(
"salted_key", F.concat(F.col("customer_id"), F.lit("_"), F.col("salt"))
)
Step 2: Explode the small side to match all salt values:
from pyspark.sql.functions import array, explode, lit
# create a salt_array list like [ 1, 2, 3, ..... , SALT_BUCKETS ]
salt_array = array([lit(i) for i in range(SALT_BUCKETS)])
exploded_customers = customers.withColumn(
"salt_val", explode(salt_array)
).withColumn(
"salted_key", F.concat(F.col("customer_id"), F.lit("_"), F.col("salt_val"))
)
Step 3: Join on the salted key:
result = salted_orders.join(exploded_customers, "salted_key").drop("salt", "salt_val", "salted_key")
Note: This multiplies the small side by
SALT_BUCKETS. If the small side is large, this can backfire. Salting works best when one side is small-to-medium and the other is large and skewed.
Choosing SALT_BUCKETS:
| Skew Severity | Recommended Salt Buckets |
|---|---|
| Mild (1 key = 5–10% of data) | 5 |
| Moderate (1 key = 10–30%) | 10–20 |
| Severe (1 key = 30–60%) | 20–50 |
| Extreme (>60%) | 50–100 |
More buckets = better parallelism, but also more memory overhead on the exploded side. Find the balance.
2. AQE Skew Join (Spark 3.0+)
If you're on Spark 3.x, the easiest fix is enabling Adaptive Query Execution's skew join optimization. It automatically detects and splits skewed partitions at runtime without any code changes needed.
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "5.0")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "256MB")
AQE flags a partition as skewed when it is 5x larger than the median AND above 256MB. It then splits it into sub-partitions and replicates the other join side as needed.
Use AQE as your first line of defense. Resort to manual salting when AQE thresholds don't catch mild-but-impactful skew, or when you need finer control.
3. Broadcast Join
If one side of the join is small enough to fit in executor memory, broadcast it. This eliminates the shuffle entirely. No shuffle means no skew.
from pyspark.sql.functions import broadcast
result = orders.join(broadcast(customers), "customer_id")
# Increase threshold if needed
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "10MB") # default
When to use: One side is under ~100–200MB after filtering. This is the fastest fix when applicable because Spark never has to shuffle the large side at all.
4. Split and Union
For a small number of extreme outlier keys, process them separately with higher parallelism, then union the results back.
HOT_KEYS = ["C001", "C002"] # identified from your skew analysis
hot_df = orders.filter(F.col("customer_id").isin(HOT_KEYS))
normal_df = orders.filter(~F.col("customer_id").isin(HOT_KEYS))
normal_result = normal_df.groupBy("customer_id").agg(F.sum("amount"))
# For the outliers, use one of the salting methods explained in the above section
hot_df = ....
# Finally union both the dataframesHere's a more detailed version:
final = hot_result.union(normal_result)
So this method is basically treating outliers differently without changing the logic for the rest of the pipeline.
5. Pre-Aggregation (Map-Side Reduction)
If you're joining on an aggregated result, reduce the data volume before the join rather than joining raw rows.
# Aggregate first: fewer rows means less skew impact on the join
agg_orders = orders.groupBy("customer_id").agg(F.sum("amount").alias("total_amount"))
result = agg_orders.join(customers, "customer_id")
This won't always be applicable, but when it is, it's one of the cheapest fixes available.
Quick Decision Guide
| Scenario | Best Approach |
|---|---|
| Spark 3.x, skew in sort-merge joins | AQE skew join |
| Small dimension table, large fact table | Broadcast join |
| Hot keys in groupBy / aggregation | Salting (two-phase aggregation) |
| Hot keys in large-to-large join | Salting with explode |
| A few extreme outlier keys | Split and Union |
| Can aggregate before joining | Pre-aggregation |