⚙️ Dynamic Resource Allocation
By default, a Spark application locks in its resources at startup: you specify a fixed number of executors, and they stick around for the entire lifetime of the job, whether they are busy or idle. Dynamic Resource Allocation (DRA) changes this by letting Spark add and remove executors at runtime based on actual workload demand.
Think of it like auto-scaling in a Spark cluster. Instead of provisioning a fixed number of executors upfront, the system allocates additional executors when workload increases and releases them when demand drops.
The Problem with Static Allocation
Consider a typical ETL pipeline that processes data in three stages:
- Read & Parse (light work): Needs 5 executors
- Join & Aggregate (heavy shuffle): Needs 50 executors
- Write output (light work): Needs 5 executors
With static allocation (spark.executor.instances = 50), you hold all 50 executors for the entire duration — including the read and write phases where 45 of them sit completely idle. On a shared cluster, those idle executors block other teams from running their jobs.
With dynamic allocation enabled, Spark scales up to 50 executors during the heavy shuffle phase and scales back down to 5 during the lighter phases, freeing resources for other applications on the cluster.
How Dynamic Resource Allocation Works Internally
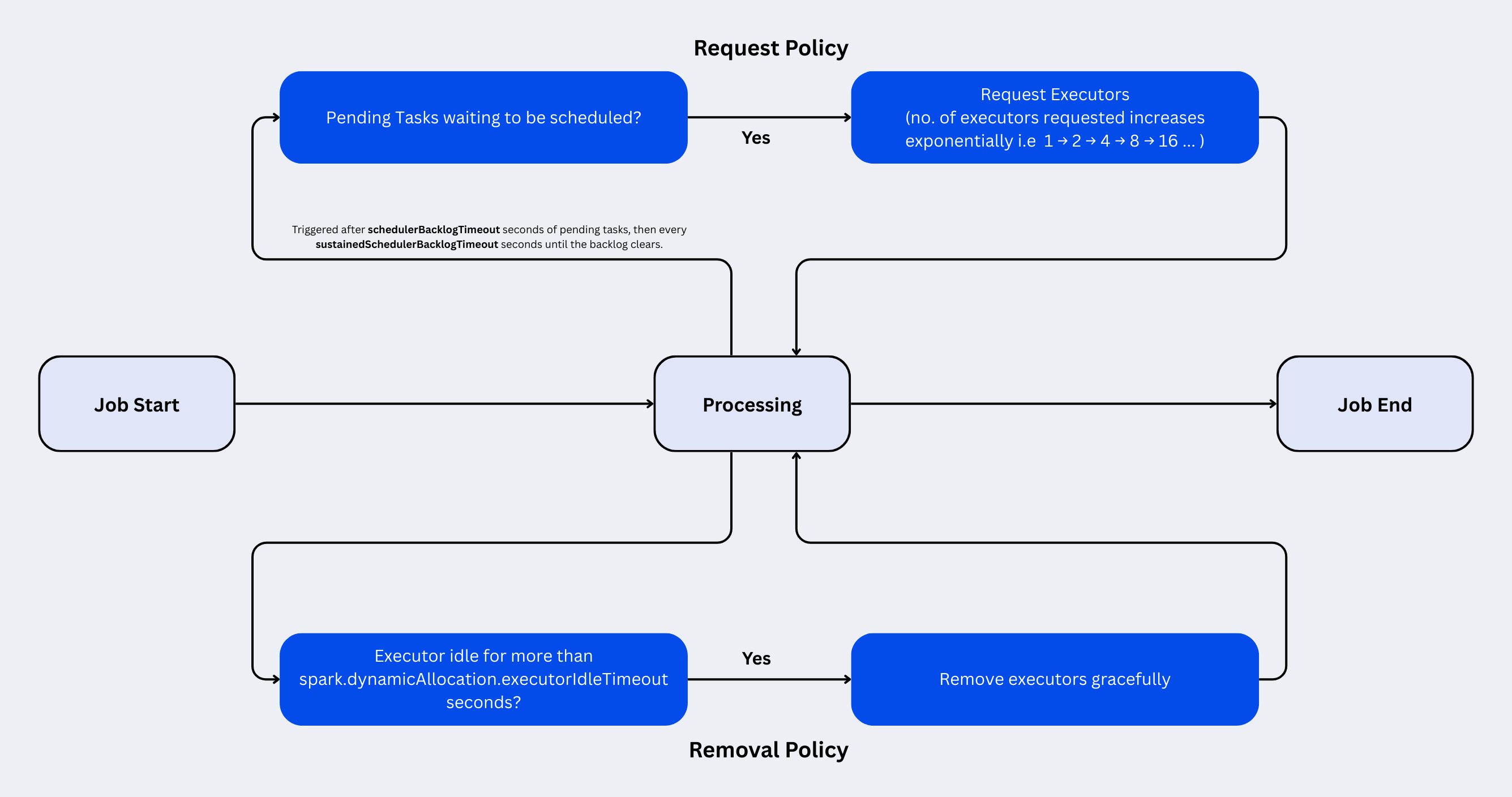
DRA operates through a continuous feedback loop between the Spark driver and the cluster manager, governed by two core mechanisms: request policies (when to add executors) and removal policies (when to remove them).
The Request Policy (Scaling Up)
Spark tracks pending tasks — tasks that are ready to run but have no available executor slot. When pending tasks exist, Spark starts requesting new executors.
The request mechanism uses exponential ramp-up to avoid overwhelming the cluster manager:
- A task has been pending for
spark.dynamicAllocation.schedulerBacklogTimeout(default 1 second). - Spark requests 1 executor in the first round.
- If tasks are still pending after
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(default 1 second), Spark doubles its request — 2 executors, then 4, 8, 16, and so on. - This exponential growth continues until either all pending tasks have slots or
spark.dynamicAllocation.maxExecutorsis reached.
The exponential strategy is deliberate: it starts cautiously (in case the backlog is momentary) but ramps up aggressively if the demand is real. A job that suddenly needs 100 executors will reach that count in about 7 rounds (1 → 2 → 4 → 8 → 16 → 32 → 64 → 100) rather than waiting 100 seconds with linear scaling.
The Removal Policy (Scaling Down)
An executor becomes a candidate for removal when it has been idle for spark.dynamicAllocation.executorIdleTimeout (default 60 seconds). "Idle" means the executor has no running tasks and no shuffle data that other stages need.
There is a special case for executors holding cached data: they use a separate, longer timeout controlled by spark.dynamicAllocation.cachedExecutorIdleTimeout (default infinity). This prevents Spark from evicting executors that store cached DataFrames or RDDs, which would force expensive recomputation.
The Full Lifecycle
External Shuffle Service
When Spark removes an executor, any shuffle data stored on that executor would normally be lost. Without mitigation, downstream stages that need that shuffle data would fail, forcing expensive recomputation of entire stages.
This is where the External Shuffle Service comes in. It is a long-running process on each worker node (independent of executors) that serves shuffle files. When enabled, executors write shuffle output to local disk and the external shuffle service handles serving that data to other executors. This decouples shuffle data from executor lifetimes.
Without External Shuffle Service: Removing an executor = losing its shuffle files = Shuffle files written by that executor must be recomputed unnecessarily. With External Shuffle Service: Removing an executor is safe because shuffle files are served by the independent shuffle service process.
Starting from Spark 3.0, there is an alternative: shuffle tracking (spark.dynamicAllocation.shuffleTracking.enabled). Instead of relying on an external service, Spark tracks which executors hold active shuffle data and simply refuses to remove them until the data is no longer needed. This avoids the operational overhead of deploying and maintaining the external shuffle service, though it may keep some executors around longer than strictly necessary.
| Approach | Configuration | Trade-off |
|---|---|---|
| External Shuffle Service | spark.shuffle.service.enabled = true | Requires deploying a separate service on every worker node. Executors can be removed freely. |
| Shuffle Tracking (Spark 3.0+) | spark.dynamicAllocation.shuffleTracking.enabled = true | No extra infrastructure needed. Executors with active shuffle data are retained until the data expires. |
Enabling Dynamic Resource Allocation
Basic Setup
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("DynamicAllocationExample")
.config("spark.dynamicAllocation.enabled", "true")
.config("spark.dynamicAllocation.minExecutors", "2")
.config("spark.dynamicAllocation.maxExecutors", "100")
.config("spark.dynamicAllocation.initialExecutors", "5")
.config("spark.dynamicAllocation.shuffleTracking.enabled", "true")
.getOrCreate()
)
spark-submit
spark-submit \
--master yarn \
--deploy-mode cluster \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=2 \
--conf spark.dynamicAllocation.maxExecutors=100 \
--conf spark.dynamicAllocation.initialExecutors=5 \
--conf spark.shuffle.service.enabled=true \
my_spark_job.py
Configuration Reference
Core Properties
| Property | Default | Description |
|---|---|---|
spark.dynamicAllocation.enabled | false | Master switch for dynamic resource allocation. |
spark.dynamicAllocation.minExecutors | 0 | Lower bound on executor count. Spark will never scale below this. |
spark.dynamicAllocation.maxExecutors | infinity | Upper bound on executor count. Set this to prevent a single job from consuming the entire cluster. |
spark.dynamicAllocation.initialExecutors | spark.dynamicAllocation.minExecutors | Number of executors to start with. Defaults to minExecutors if not set. |
Scaling Up Properties
| Property | Default | Description |
|---|---|---|
spark.dynamicAllocation.schedulerBacklogTimeout | 1s | How long tasks must be pending before the first executor request. |
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | 1s | Interval between subsequent executor requests (with exponential doubling). |
Scaling Down Properties
| Property | Default | Description |
|---|---|---|
spark.dynamicAllocation.executorIdleTimeout | 60s | How long an idle executor waits before being removed. |
spark.dynamicAllocation.cachedExecutorIdleTimeout | infinity | Idle timeout for executors holding cached data. Set this to a finite value if you want cached executors to eventually be reclaimed. |
Shuffle Properties
| Property | Default | Description |
|---|---|---|
spark.shuffle.service.enabled | false | Enables the external shuffle service. Required for DRA unless shuffle tracking is used. |
spark.dynamicAllocation.shuffleTracking.enabled | false | Enables shuffle file tracking as an alternative to the external shuffle service (Spark 3.0+). |
spark.dynamicAllocation.shuffleTracking.timeout | infinity | Maximum time shuffle data is retained on an idle executor before it becomes removable even if its shuffle files are still referenced. |
Benefits of Dynamic Resource Allocation
1. Cluster Utilization
On shared clusters, static allocation leads to resource hoarding. A job configured with 50 executors holds them for its entire lifetime even during idle phases. With DRA, those executors are returned to the cluster pool within 60 seconds of becoming idle, making them available to other applications.
2. Cost Efficiency on Cloud
On cloud platforms (EMR, Dataproc, Databricks), you pay per resource-hour. A 3-hour job that needs 100 executors for only 30 minutes of heavy processing wastes 2.5 hours × 100 executors worth of compute costs. DRA combined with cluster auto-scaling can reduce cloud costs by 40-70% for bursty workloads.
3. Handling Variable Workloads
Jobs that process different data volumes across runs (e.g., daily batch jobs where Monday's volume is 5x Saturday's) benefit without requiring manual tuning per run. DRA adjusts the executor count to match each run's actual data volume.
4. Multi-Tenant Fairness
On YARN or Kubernetes clusters shared by multiple teams, DRA prevents one application from monopolizing resources during its idle phases, improving overall cluster throughput and reducing queue wait times for other jobs.
5. Simplifying Configuration
Without DRA, teams spend significant effort tuning spark.executor.instances for each job. Too few executors and the job is slow; too many and you waste resources (and money). DRA replaces this guesswork with a simple min/max range.
Practical Examples
Example: ETL Pipeline with Variable Stages
A pipeline that reads from S3, performs a heavy join, and writes to a data warehouse. Each stage has vastly different resource needs.
spark = (
SparkSession.builder
.appName("ETL_Pipeline")
.config("spark.dynamicAllocation.enabled", "true")
.config("spark.dynamicAllocation.minExecutors", "2")
.config("spark.dynamicAllocation.maxExecutors", "50")
.config("spark.dynamicAllocation.initialExecutors", "5")
.config("spark.dynamicAllocation.shuffleTracking.enabled", "true")
.getOrCreate()
)
# Stage 1: Read (light) — Spark uses ~5 executors
orders = spark.read.parquet("s3://data/orders/") # 100 GB
customers = spark.read.parquet("s3://data/customers/") # 500 MB
# Stage 2: Join + Aggregate (heavy) — Spark scales up to ~40 executors
result = (
orders
.join(customers, "customer_id")
.groupBy("region", "product_category")
.agg(
sum("amount").alias("total_revenue"),
countDistinct("order_id").alias("order_count")
)
)
# Stage 3: Write (light) — Spark scales back down to ~5 executors
result.write.mode("overwrite").parquet("s3://data/revenue_summary/")
What happens at runtime:
- Application starts with 5 executors (initial).
- Reading parquet files keeps ~5 executors busy. No scale-up needed.
- The join triggers a shuffle with hundreds of pending tasks. DRA detects the backlog and exponentially scales to ~40 executors within seconds.
- After the join completes and writing begins, most executors go idle. After 60 seconds of idle time, DRA scales back down.
When NOT to Use Dynamic Resource Allocation
| Scenario | Why DRA Hurts |
|---|---|
| Short-lived jobs (< 2 minutes) | Executor startup overhead (JVM launch, dependency shipping) can be 10-30 seconds per executor. For a job that finishes in 90 seconds, the scaling latency costs more than it saves. |
| Perfectly predictable workloads | If every run processes the same data volume with the same query, a well-tuned static allocation avoids the overhead of the DRA scheduling loop. |
| Latency-sensitive applications | The scale-up delay (detecting backlog → requesting executors → launching JVMs) adds seconds of latency. For sub-second batch jobs, static allocation guarantees resources are pre-allocated. |
| Single-tenant dedicated clusters | If no other application shares the cluster, releasing executors has no benefit — the resources sit idle on the cluster anyway. |
Common Pitfalls
1. Setting spark.executor.instances alongside DRA
Setting spark.executor.instances effectively tells Spark "I want exactly this many executors." On some cluster managers, this silently disables DRA. Always omit spark.executor.instances when DRA is enabled, or ensure spark.dynamicAllocation.enabled=true is set explicitly to override it.
2. Forgetting shuffle data protection
Without the external shuffle service or shuffle tracking, removed executors take their shuffle files with them. This causes FetchFailedException errors and stage retries, making the job slower than static allocation. Always enable one of the two shuffle protection mechanisms.
3. Setting maxExecutors too high
On a shared cluster with a YARN fair-scheduler queue, a single DRA enabled job can grab all available resources during its peak, starving other applications. Set maxExecutors to a reasonable ceiling that reflects your fair share of the cluster.
4. Too-aggressive idle timeout
Setting executorIdleTimeout below 30 seconds causes executor thrashing — executors are removed and re-requested repeatedly, paying JVM startup costs each time. The default of 60 seconds is a good balance for most batch workloads. For streaming, use 120-180 seconds.
5. Ignoring cachedExecutorIdleTimeout with .cache()
If your job caches large DataFrames and cachedExecutorIdleTimeout is set to its default of infinity, those executors will never be released even if the cached data is never accessed again. Set a finite timeout if cache reuse is uncertain.
Summary
| Aspect | Static Allocation | Dynamic Resource Allocation |
|---|---|---|
| Executor count | Fixed at submit time | Adjusts at runtime based on demand |
| Scale-up | N/A | Exponential ramp-up on pending tasks |
| Scale-down | N/A | Idle executors removed after timeout |
| Cluster utilization | Resources held for full job duration | Resources released when idle |
| Configuration effort | Must tune executor.instances per job | Set min/max range and let Spark decide |
| Shuffle data safety | Not a concern (executors persist) | Requires external shuffle service or shuffle tracking |
| Best for | Predictable, short, single-tenant workloads | Variable, long-running, multi-tenant workloads |